Go 语言性能调试与分析工具:pprof 用法简介
pprof 是 Google 开发的一款用于数据分析和可视化的工具。
最近我编写的 go 程序遇到了一次线上 OOM,于是趁机学习了一下 Go 程序的性能问题排查相关知识。其基本路线是:先通过内置的 net/http/pprof 模块生成采集数据,然后在使用 pprof 命令行读取并分析。Go 语言目前已经内置了该工具。
本文不会介绍 pprof 的太多细节,只关注主要流程(主要的是太细的我现在也不会)。
数据采集
由于 Go 语言内置了对 pprof 的支持,因此无需额外安装其它依赖,只需要在程序入口处引入相关包,并且启动一个服务即可:
package main |
需要注意的是 pprof 服务需要使用独立的协程运行,否则会阻塞代码运行。添加这段代码后,程序除了运行原本的逻辑外,还将额外监听一个端口(此处为 6060),在本地运行程序,打开 http://localhost:6060/debug/pprof/,将看到如下界面:

数据采集服务即启动成功。
我刚开始看到这段代码的时候有点好奇:为什么它的 handler 传了 nil,但是却能够启动一个 debug 服务呢?
后来仔细看了一下源码后就发现,handler 如果传 nil 的话,即默认为 DefaultServeMux:
// net/http/server.go |
而 net/http/pprof/pprof.go 在 init 函数中,向 DefaultServeMux 注册了几个路径:
// net/http/pprof/pprof.go |
因此,如果启动一个 handler 为 nil 的 http 服务,即默认会添加上 pprof 的一系列路由。
这个 web 界面上面有一些链接,每个链接代表一个监控项目,页面下方也对它们做了一些解释。直接点进去的话,会展示一些数据,但是目前这些数据比较原始,可读性不佳。但好消息是,后面可以通过 pprof 命令行对它们进行进一步的分析。
指标解释
除了 cmdline 和 trace 以外,上面的每一个链接都代表一种指标。常用指标如下:
- profile:CPU 占用率
- heap:当前时刻的内存使用情况
- allocs:所有时刻的内存使用情况,包括正在使用的及已经回收的
- goroutine:目前的 goroutine 数量及运行情况
- mutex:锁争用情况
- block:协程阻塞情况
pprof 命令行工具
程序运行一段时间后,我们就可以通过 pprof 命令行来进行数据分析了。打开一个终端环境,输入 go tool pprof http://localhost:6060/debug/pprof/allocs 并按下回车,就能看到如下界面:
此时即连接成功。接下来在终端中操作,将展示命令行启动时刻的监控数据。输入 help 可以展示所有的命令,输入 help [command] 可以展示具体命令的帮助界面。
现在回到上面那个链接 http://localhost:6060/debug/pprof/allocs,观察一下它的构成:
- 首先,是一个常规的 host+port 组合,由于我们在本地启动服务且指定监听 6060 端口,因此这里填写
localhost:6060。但是它同样也支持远程连接。即对部署在服务器上的程序进行分析。只要遵循同样的格式,以及保证路径可访问即可; - 然后跟随的是一个
/debug/pprof/路径,此为固定值; - 最后是一个
allocs,这个代表某一种监控指标。回到刚刚的那个 web 界面,除了cmdline以外,每一个链接都代表一种指标,可以在此处直接填入,即可更换分析目标。
命令行实际上读取的是一个由 pprof web 服务提供的 .pb.gz 文件,它是一个通过 gzip 压缩的 protocol buffer 数据。其源码在 runtime/pprof 包中。
type profileBuilder struct { |
如果要退出 pprof,可以输入 exit 并回车。
下面介绍几个常用命令。
top:列出数据
要列出当前资源的占用情况,可以在 pprof 中使用 top 命令:
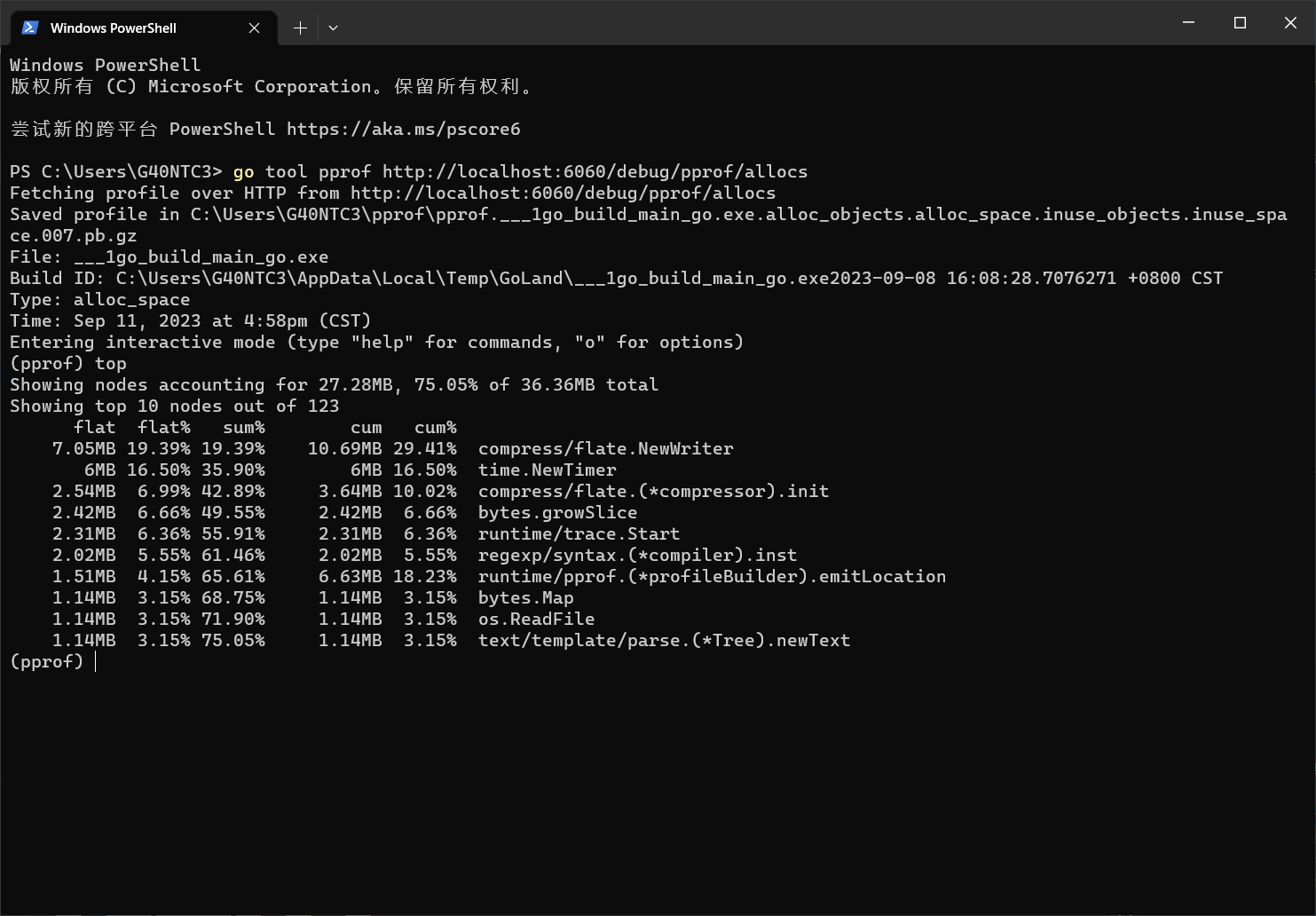
默认会按照资源占用率从高到低,显示 10 条数据。
它上面的每项指标(flat/flat%/sum/cum/cum%)大致理解就是数值越大则资源占用情况越严重。结果默认按照 flat 排序。其指标含义的详细解释可以参考 pprof 文档:
flat: the value of the location itself.
cum: the value of the location plus all its descendants.
cum 是 cumulative(累积) 的缩写。
我的理解是:
- flat:函数内所有直接语句的时间或内存消耗;
- cum:函数内所有直接语句,以及其调用的子函数的时间或内存消耗;
- sum:没有在文档中找到对应解释,但是通过观察可以发现,它是 flat% 的累加值。
通过一个例子来解释:
func foo(){ |
这个函数总共将花费 1 + 2 + 3 + 4 = 10 秒,其中:
- flat 等于 3,因为该函数的直接操作只有 step3
- cum 包含所有直接语句以及子函数的消耗,即 step1 + step2 + step3 + step4
- step 4 的 sum% 为 step1、step2、step3、step4 的 flat% 总和
list:显示详情
当发现某个函数资源占用情况可疑时,可以通过 list 函数名 定位到具体的代码位置。举例:
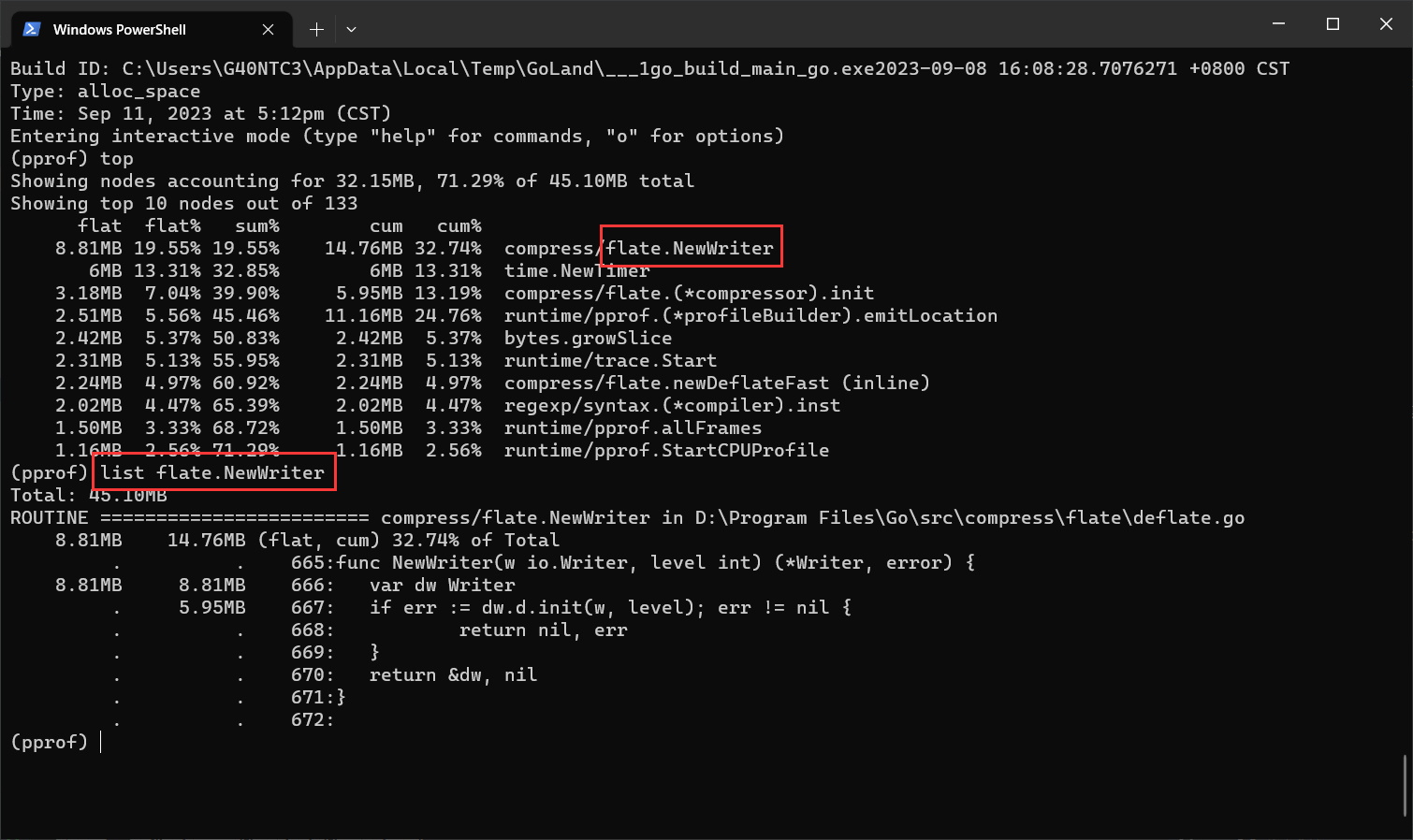
该案例显示,在第 666 行处,dw 占用了 8.81MB 的内存,667 行占用 5.95MB 内存,该函数合计占用 14.76 MB。
此处也可以对应到上面提及的 flat/cum 含义:666 行计入 flat,666 + 667 行计入 cum。
web:可视化分析
在使用 web 命令之前需要做一个准备工作:安装 Graphviz 工具,并将它添加到系统 path 中。
直接在命令行输入 web,pprof 将打开一个浏览器,并展示一个可视化的分析界面:
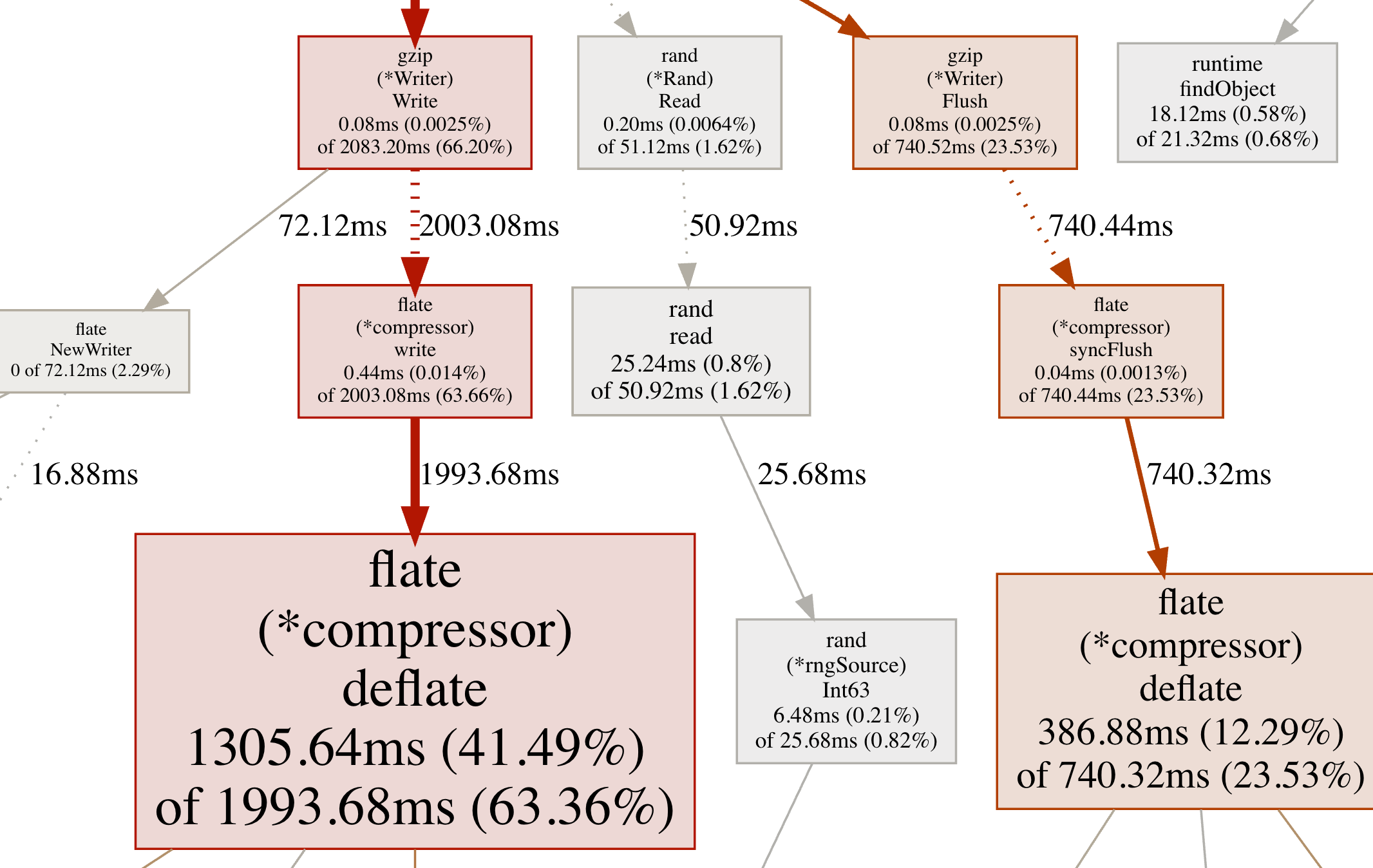
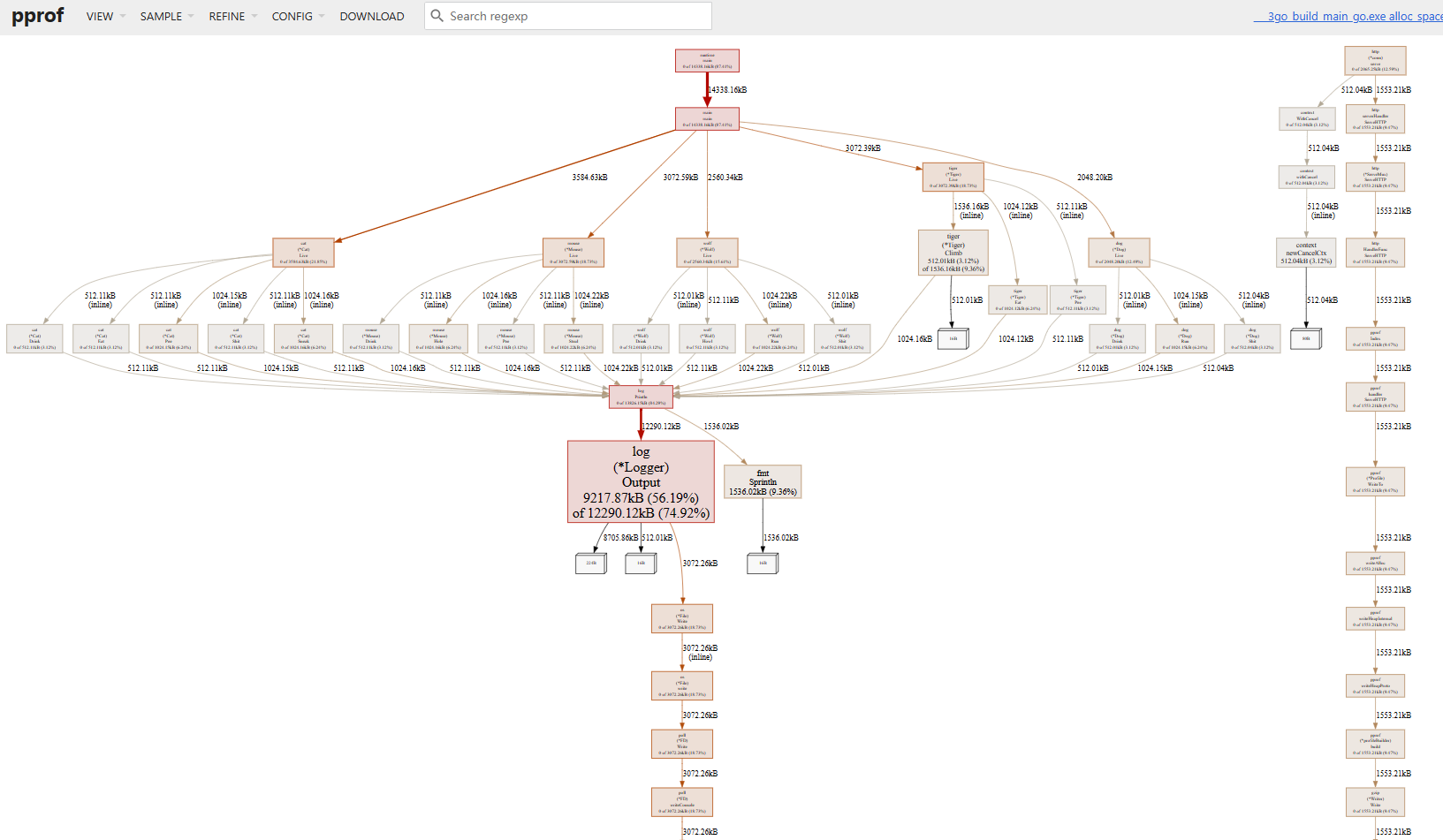
在 web 界面上将显示函数的完整调用链路,界面可以通过鼠标拖拽、缩放。其图形详细的解释(来自 pprof 文档):
- 节点颜色与 cum 值有关:
- 正值大的为红色
- 负值大的为绿色(负值通常在 profile 对比时出现)
- 值接近 0 的为灰色
- 节点的字号与 flat 的绝对值有关:值越大则字号越大
- 边的粗细与该路径下的资源使用有关:资源使用越多则线条越粗
- 边的颜色与节点颜色类似
- 边的形状:
- 虚线:两个节点之间的部分节点被移除了(间接调用)
- 实现:两个节点之间存在直接调用关系
粗略地来说,每个节点的方块越大、线条越粗、颜色越红,则代表资源占用情况(相对来说)越严重,需要重点关注。
对应上图的例子来说:
(*Rand).Read的 flat 值较小(字号较小、灰色)(*compressor).deflate的 flat 值与 cum 值均较大(字号较大、红色)(*Writer).Flush的 flat 值较小(字号较小),但 cum 值较大(红色)(*Writer).Write与(*compressor).write之前的线条是较粗、红色的虚线,因此它们之间的某些节点被移除了,且使用的资源较多(*Rand).Read与read之前的线条是较细、灰色的虚线,因此它们之间的某些节点被移除了,且使用的资源较少read与(*rngSource).Int63之前的线条是较细、灰色的实线,因此它们之间存在直接调用关系,且使用的资源较少
sample_index:切换采样值
某些监测类型会拥有多种采样值,可以通过 help sample_index 查看当前可用的采样值:
(pprof) help sample_index |
通过 sample_index=i 可以切换采样方式。切换后再次使用 top 命令,展示的结果将会有些区别。
pprof 的 Web 界面
可以通过 go tool pprof -http=:8888 http://localhost:6060/debug/pprof/allocs 命令直接打开一个 web 界面,这个 web 界面将拥有与命令行类似的功能,并且可以显示火焰图。同样,这个命令需要先安装 Graphviz 工具。
- View 菜单展示的几项功能:
- Top 与命令行的 top 类似
- Graph 与命令行的 web 类似
- Peek/Source 与 list 命令类似:在 Top 选中一行,或者 Graph 选中一个节点后,切换到 Peek 或 Source 界面,将展示该行/节点的代码详情
- Frame Graph 为火焰图
- Disassemble:查看汇编代码
- Sample 菜单与命令行的 sample_index 类似
火焰图
此处以 Frame Graph (new) 举例。
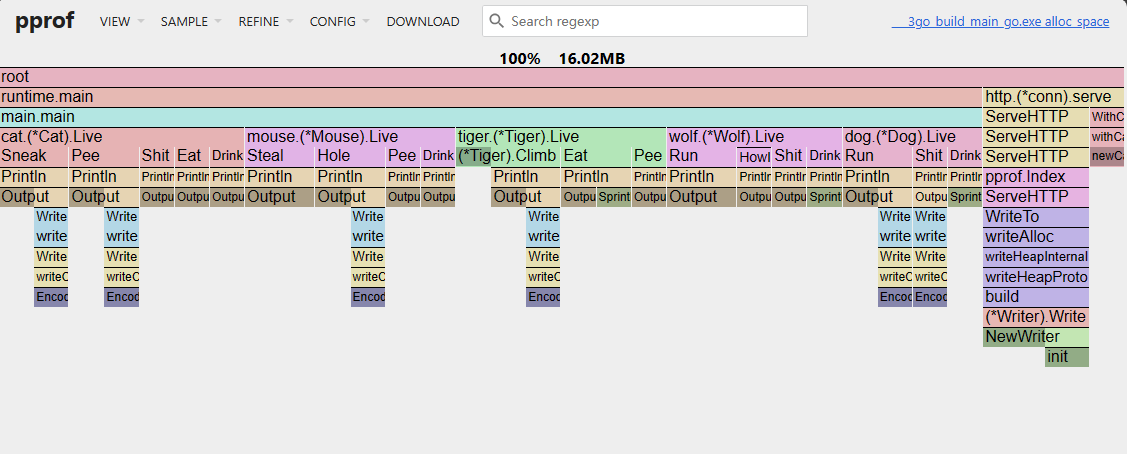
解释:
- 节点的颜色是由它的包名决定的,相同包名的节点将拥有相同的颜色
- 节点的字号可能会有区别,但是与上面的图形不同的是,此处的字号仅为适应其节点大小,并无其它含义
- 上方的节点为调用者,下方的节点为被调用者
- 节点的宽度表示资源使用情况,越宽则资源使用越多
- 其总宽度代表 cum
- 去除其子节点后,剩余的宽度代表 flat
- 如果上下节点之间没有边框,则表示这两个函数被“内联”了。关于内联的具体含义,可以参考 Go: Inlining Strategy & Limitation
一个函数可能会被多个不同的函数调用,因此 pprof 对传统的火焰图进行了改良:点击任意函数将显示所有最终导向该函数的调用栈,而非仅当前点击节点的调用栈。