做了一个 b 站视频下载与 mp3 转换工具
b 站上的歌姬,很多歌只发布在 b 站。比如说直播时唱的歌,或者一些发布到正经音乐平台上会有版权问题的歌。然而,对于爱听歌的人来说,b 站的听歌体验实在是太差了,这里就不展开细说。
我习惯用网易云听歌。网易云虽然版权方面很惨,但有它一个很好用的功能:云盘。每个用户有 60G 的云盘容量,基本用不完,不管是什么歌,有没有版权,只要上传上去了就能随时随地听。因此,我的目标是,希望可以有一个自动化的工具,帮我把 b 站上的歌以 mp3 的格式下载下来,让我可以上传到云盘,这样我就可以用网易云听歌了。
综上所述,我就做了这么一个小工具:bv2mp3 ,这是一个开源工具,完整的代码可以在代码仓库中找到。下面,我主要讲一下这个工具的实现思路以及优化过程。
在这之前
起初,我还是不愿意自己造轮子的,毕竟我觉得这应该是个非常 common 的需求,应该会有不少东西可以拿来直接用。
最开始的时候,我尝试使用了网络上的一些随处可见的在线服务,搜索“b 站视频下载”可以找到很多相关的在线网站。此类服务通常来说是能用的,但是当需要下载的量一旦大起来以后,它就显得非常麻烦了。比如说它需要看广告,或者下载的质量参差不齐,并且需要下载后手动再转一次MP3,非常麻烦。
在受够了此类工具以后,我开始转向一些付费工具。我找到了一款比较强大的“哔哩哔哩助手”浏览器插件。只要付费,它就能提供将视频直接下载为 mp3 的功能。并且可以直接在 b 站页面上操作,相对来讲比较好用。但是用了几个月下来以后,仍然觉得还不够好:
- 首先,当然是因为它要付费;
- 其次,我要下载的一般都是整个播放列表,而这款插件只能一次下载一个分集,这意味着我要将分集一个一个地打开,再一个一个地打开助手菜单,找到并点击MP3下载按钮;
- 有时候,我甚至需要一次性下载多个播放列表,这种体验的痛苦就成倍增加了。
总的来说,它虽然能用,但是用户体验依旧很原始。
我想要的是:可以一次性下载整个列表里面的所有视频,甚至一次性下载多个列表,然后将他们批量转为 mp3 的工具。
找了一圈 GitHub,虽然有类似的工具,但都不能完美契合我的需求。因此我决定:这次还是自己来吧!
程序主框架
我希望我做的工具可以尽可能地简单(无论是从使用还是开发层面):
- 它是高度定制化的,可以只为我服务(当然如果可以帮助到其它人就更好了);
- 它不需要界面,因为写界面是很麻烦的事情,只需要一个命令行就好了;
- 它可以一键帮我完成上述所有事情:
- 下载一个或多个列表里面的所有视频
- 将视频转为mp3
- 拥有批量化自动命名、自动失败重试等其它基本功能
- 上传到网易云盘这一步,由于没有找到网易云的可用接口,因此这一步仍需手动
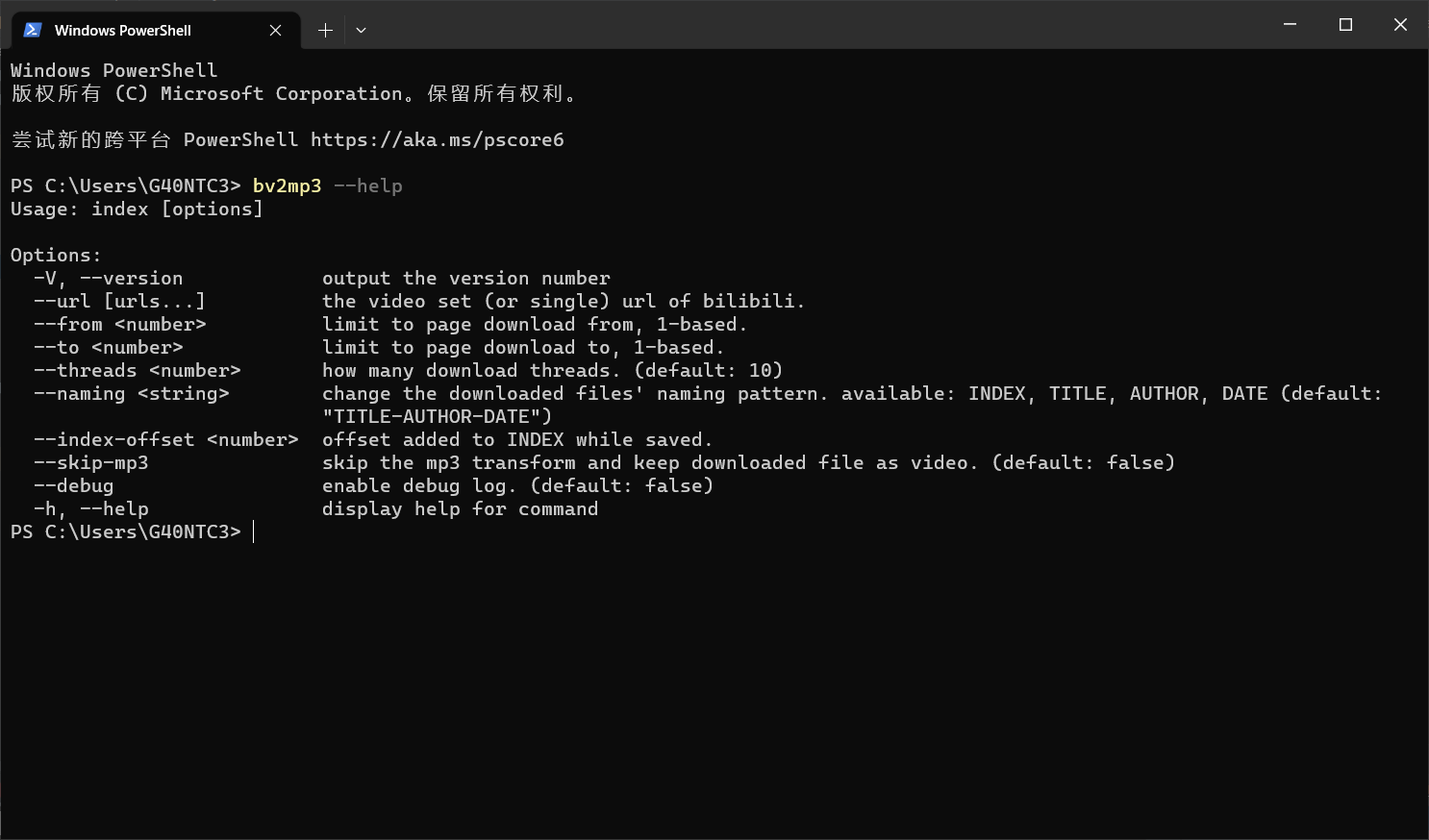
从“尽可能地简单”为出发点,总体技术栈自然是选择我最熟悉的 Node.js,并且是 v16+,以此直接开启 type=module,舍弃 cjs 的裹脚布。
然后,首选 tj 的 commander.js 来实现命令行程序。
那么,问题来了,将一个 b 站视频下载下来并且转为mp3,要分几步?
爬取网页
以 https://www.bilibili.com/video/BV1wV411t7XQ 为例。这个列表里面共有 336 首歌,我需要把它们全部下载下来。
点击列表中的视频,仔细观察可以发现,它们的 url 是有类似的模式的,比如:
- 第一集是 https://www.bilibili.com/video/BV1wV411t7XQ?p=1,或者如果不加
p=1,默认就是第一集 - 第二集是 https://www.bilibili.com/video/BV1wV411t7XQ?p=2
- 第三集是 https://www.bilibili.com/video/BV1wV411t7XQ?p=3
- 以此类推…
可以发现它们前面的格式都是一样的,区别只在后面的 ?p=x。
那么我需要做的事就是:
- 程序接收一个链接
- 找到链接里面共有多少集
- 然后分别组装每一集的 url 并下载
从国际惯例来讲,为了实现步骤2,我需要去爬取这个网页,解析里面的 HTML,找到跟集数有关的节点。但是 b 站是个特例,它有更方便的办法。它的 HTML 网页上挂载了一个 __INITIAL_STATE__ 对象,下面就有准确的信息。
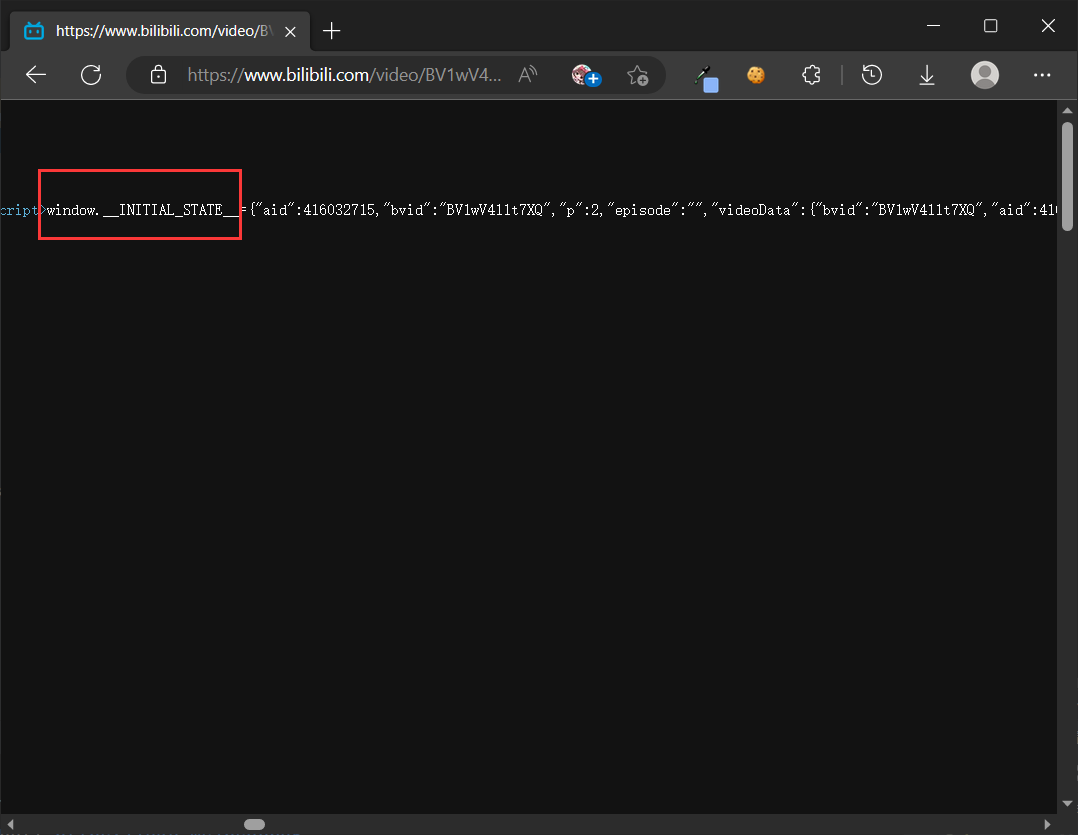
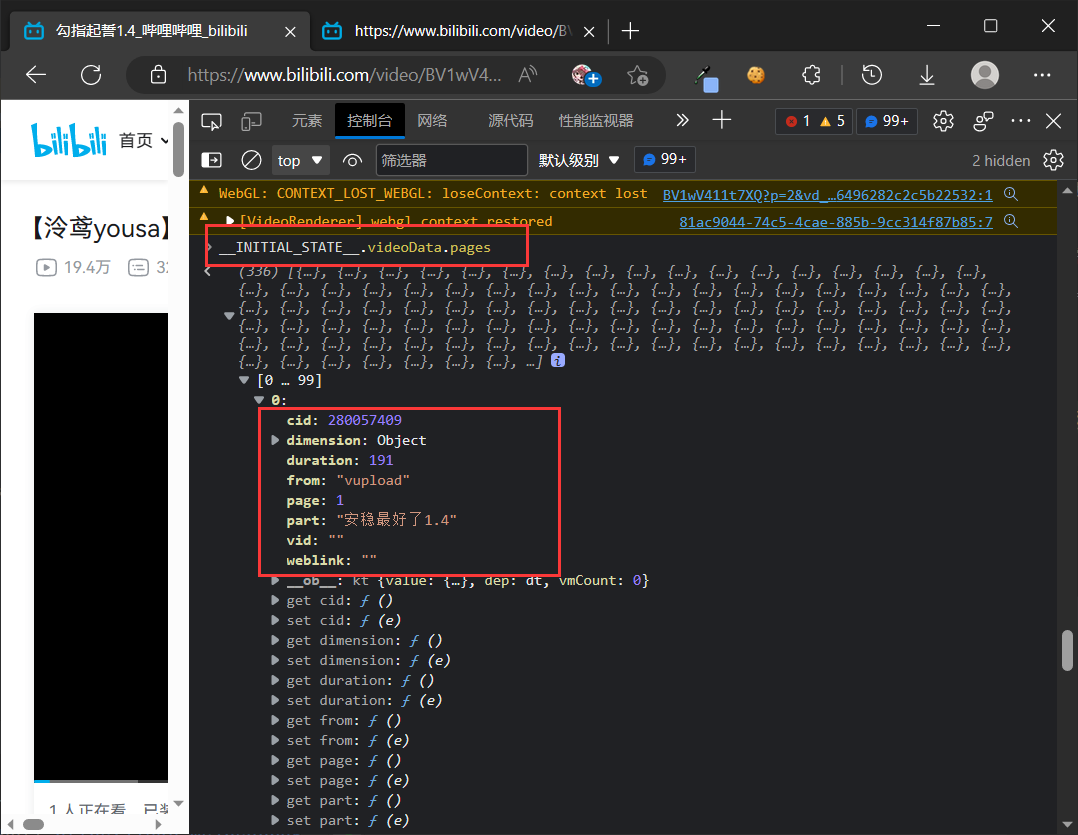
因此,这一步变得非常简单,只需要解析这个对象即可。
export async function getDataByUrl(url) { |
这样一来就拿到了这个列表的分集信息,接下来要解决下载问题。
下载视频文件
之前的网页上没有找到视频下载地址的信息,因此这部分需要单独的接口。通过在 GitHub 上寻找类似项目得到了一个可用方案:
const params = `cid=${cid}&module=movie&player=1&quality=112&ts=1`; |
其中这个 cid 在之前的 pages 变量中是存在的,然后需要将 [apikey] 替换为实际的 apikey(大家都把它放在仓库中了,我也不例外,取之 GitHub 用之 GitHub,反正不是我泄密的就不算泄密),并且用 md5 算法做签名。至于其它变量,不太明白它们的实际意义。
这个工具主攻 mp3 转换,因此也不需要关心视频质量、水印等问题,突出一个能用就行。
调用接口,可以得到一个 flv 的下载链接:
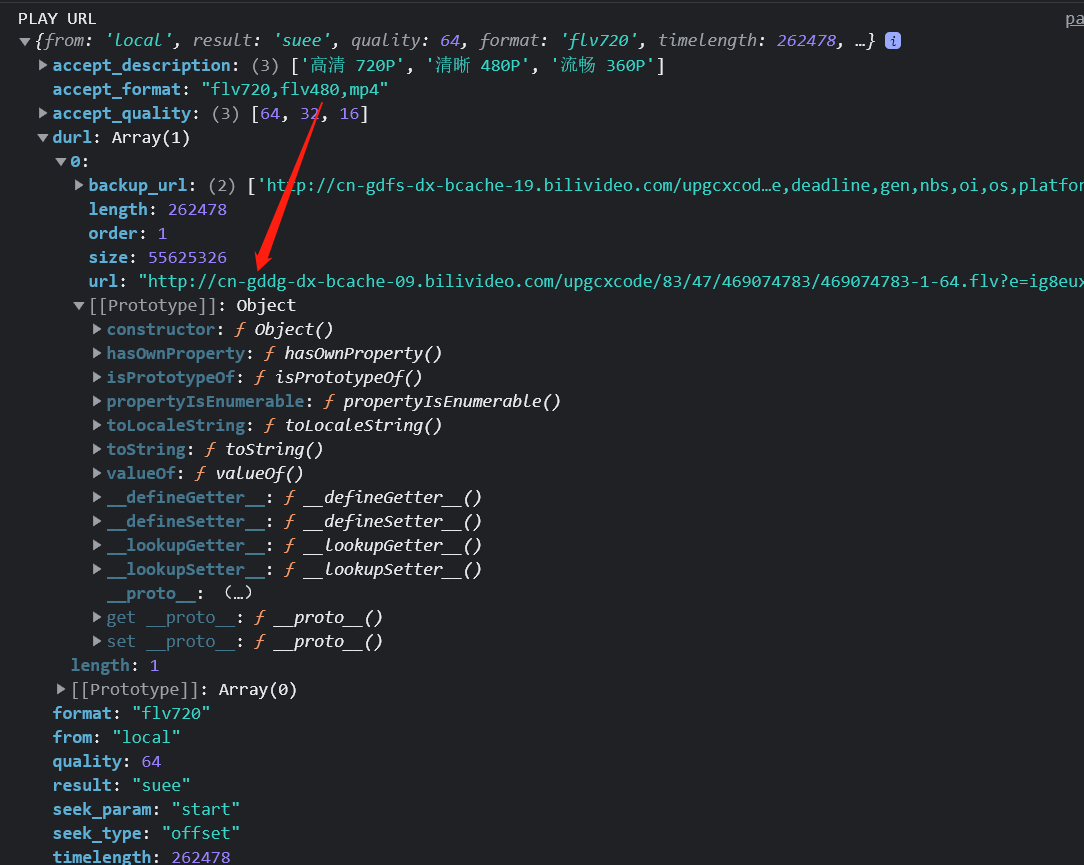
然后就是简单粗暴的下载环节:
agent({ |
转换mp3
在最初的版本,我能直接想到的工具就是 ffmpeg ,代码里面简单粗暴地直接调用 ffmpeg:
import { exec } from 'child_process'; |
这么做,能用。但是用起来不太舒心。因为我毕竟要先下载一个 C 语言版本的 ffmpeg,并且把它设置到系统 Path 中,这样程序才能正常调用到它。这个对我来说是个一次性的工作,倒也没啥,但是对于想要使用这个工具的其它用户来说就很可能劝退了。但是不管怎么说,主流程到现在已经结束了。我已经完成了下载整个视频列表并且转换成 mp3 的程序,它能正常工作了。
但是,它现在还非常粗糙,需要在细节上做进一步的打磨。
细节优化
并行下载
我最早想到的并行方案,是用 lodash.chunk 将视频分割成一个个的小块(如:10个视频一块),处理完一个块再处理下一个块。
const pageChunks = chunk(pages, 10); |
这种方法好处是确实能实现并行下载,并且实现起来非常简单。至于它存在的问题,后面还会提到。
展示进度条
进度条对于一个下载工具来说至关重要,尤其是并行下载多个任务的时候。好在我不用自己实现,即使是命令行界面也有优秀的现成工具:progress 以及 multi-progress 。
而我只需要对它做一点简单的封装即可:
import Progress from 'multi-progress'; |
agent({ |
失败重试
b 站的视频下载地址有一定的失败概率,因此做了一个简单粗暴的失败重试逻辑:
export async function download2mp3({ url, index }) { |
这个方法永远不会抛错,只要出错了就一直重试下去。对于我这种脚本程序来说,非常好用。
自定义命名
我希望下载下来的文件可以按照我想要的规则去命名,这样不管是从哪里下载的文件,最后都不会显得杂乱无章。
这个功能的实现部分参考了“哔哩哔哩助手”这个浏览器插件的做法,使用了 pattern 命名法:
export function getName(index, title, author, date) { |
这个 naming 参数的默认值是 TITLE-AUTHOR-DATE,也就是 视频标题-视频作者-视频上传日期。它会将这个命名模式套用到具体的文件上。这个东西的用法是很灵活的。比如说,我希望我下载的文件要有序号,另外视频的上传者并不是演唱者,我希望显示演唱者。那么我常用的命名模式是 INDEX-TITLE-yousa-DATE。注意这里第三个坑位变成了 yousa,它并不在支持的 pattern 中,代表的含义就是它将固定为 yousa,不会再被替换了。
ffmpeg 优化
做开源软件的好处,除了得到用户的肯定外,我永远可以从别人那里学到新的东西,比如:
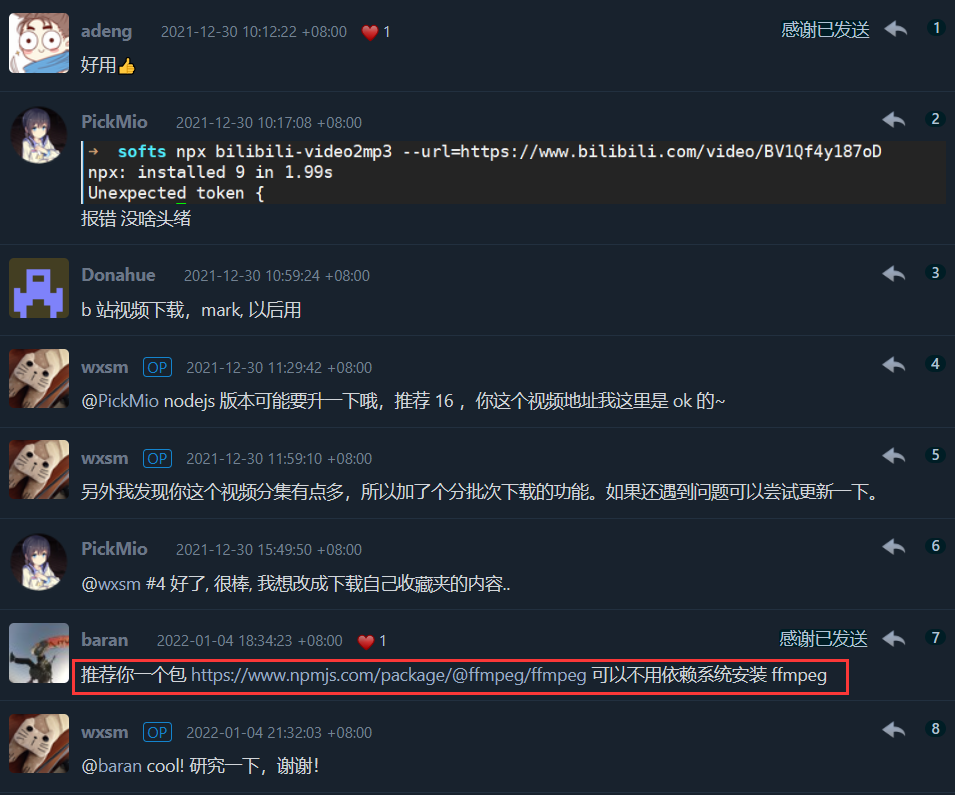
原来 ffmpeg 已经有了 wasm 版本:ffmpeg.wasm 。将 ffmpeg 替换为 ffmpeg.wasm 后,使用时使就不再需要预先安装 C 语言版本的 ffmpeg,也无需设置 path,用户体验可以得到大幅度的提升。
修改后的转换代码(大概长这样):
import { fetchFile, createFFmpeg } from '@ffmpeg/ffmpeg'; |
看起来很美好。但实际运行起来后,发现一个令人哭笑不得的问题:
Rejection (Error): ffmpeg.wasm can only run one command at a time |
它一次居然只能跑一个命令!也就是说,它跟我的多线程下载并不能很好地兼容。当多个文件同时下载完成后,如果即刻开始多个转换,程序就报错了。因此我需要做一个流程控制:当转换正在进行的时候,其它下载完的视频文件需要先进入排队状态:mp3 转换的过程得一个一个来。
根据上述思想修改一下 flv2mp3,用一个全局变量来控制同一时间只有一个任务能进来转换:
// 将 ffmpeg 实例提到外面来,全局共用 |
虽然缺点有点夸张,但思考再三,我觉得跟 C 语言 ffmpeg 的使用体验比起来,这种方式还是更优一点。
并行优化
前面有提到我一开始设计的并行方案:
用 lodash.chunk 将视频分割成一个个的小块(如:10个视频一块),处理完一个块再处理下一个块
这种办法好处是实现简单,但缺点也很明显:b 站似乎对每个下载地址做了限速,因此有时候一个块里面一两个文件特别大,其它文件都下载完了,它还在慢悠悠的下载,让人感到浪费生命。实际上,它可以立即开始余下的其它任务的,只要保证正在运行的总的任务数量不超过设定的数值即可。
也许你会问:既然这么麻烦,为什么不全部同时开始下载呢?这个方式实际上我也试过,但是一旦同时下载的任务太多了(比如上面的一个链接,有 300 多个视频,更何况我们还能支持一次输入多个链接),下载的出错率会陡增。这样反而会导致效率急剧下降。因此是不可取的。
为了解决这个问题,我将并行控制的代码又优化了一下,摒弃了 chunk 的做法:
// 最大的进程数,默认为 10 |
这样一来,任务并行的效率得到了极大的提升:同时进行中的任务数量会始终保持在最接近允许的最大数量的水平。充分利用上电脑的带宽。
ffmpeg.wasm 优化
上面我们解决了 C 语言 ffmpeg 带来的不适,但是同时引入了新的问题:同时只能运行一个转换任务,其它的下载完的视频要排队。这个问题在并发问题得到优化后被极大地放大了:经常是所有文件都已下载完,却仍有一大批文件在等待转换。这让人感到非常痛苦:我写的程序不应该这么蠢的。
因此,我又开始考虑这个问题的解决方案了:既然一个 ffmpeg.wasm 进程只能跑同时跑一个任务,那我为每个下载任务都单独开一个进程行不行?
Node.js 提供了一个 child_process.exec 函数,可以用来运行一个命令行任务。在最初的版本中,调用 C 语言的 ffmpeg 的任务也是通过这个完成的。现在,我能否利用它来调用 ffmpeg.wasm 呢?
先将 flv2mp3 的函数,抽离为一个独立的文件,在这个文件中直接运行转换:
(async () => { |
然后改造原来的 flv2mp3 文件:
export function flv2mp3(filename) { |
改造完后实测,这确实将该问题解决了。现在多个文件同时下载完后,也可以同时开始转换了!虽然同时开启多个转换进程后 CPU 的利用率会飙涨、风扇狂飙,但相比节约的时间来说,这都不是问题。
写在最后
这个工具现在看起来很简单,并没有什么过人之处。但是我在实现它的时候还是花了非常多的时间去调试。比如说,在加上了进度条后,整个 stdout 都会被进度条占据,console API 难以再打印出错误信息。因此我只能给它设计了一套基于文件的日志系统用来 debug。又比如说,项目早期在下载文件的时候,程序经常莫名奇妙地、没有任何征兆地就退出了,我需要非常细心地去寻找每一个可能抛错的点,尽可能优雅地捕获所有错误。
至今为止我已经用它下载了一千多首 yousa 的歌。这种自己开发工具来解决自己的问题,并且一步步地将它变得完美以及节约生命的愉快感真的是非常棒的。
最后更开心的当然是,我做的工具同时也能给其它素不相识的人带来愉悦: