Node.js 包管理器发展史
在没有包管理器之前
正确来说 Node.js 是不存在没有包管理器的时期的。从 A brief history of Node.js 里面可以看到,当 2009 年 Node.js 问世的时候 NPM 的雏形也发布了。当然因为 Node.js 跟前端绑得很死,这里主要谈一谈前端在没有包管理器的时期是怎样的。
那时候做得最多的事情就是:
- 网上寻找各软件的官网,比如 jQuery;
- 找到下载地址,下载 zip 包;
- 解压,放到项目中一个叫 libs 的目录中;
- 想更方便的话,直接将 CDN 链接粘贴到 HTML 中。
四个字总结:刀耕火种。 模块化管理?版本号管理?依赖升级?不存在的。当然,那时候前端也没有那么复杂,这种模式勉强来说也不是不能用。
npm v1-v2

2009 年,Node.js 诞生,npm(Node.js Package Manager)的雏形也正在酝酿。
2011 年,npm 发布了 1.0 版本。
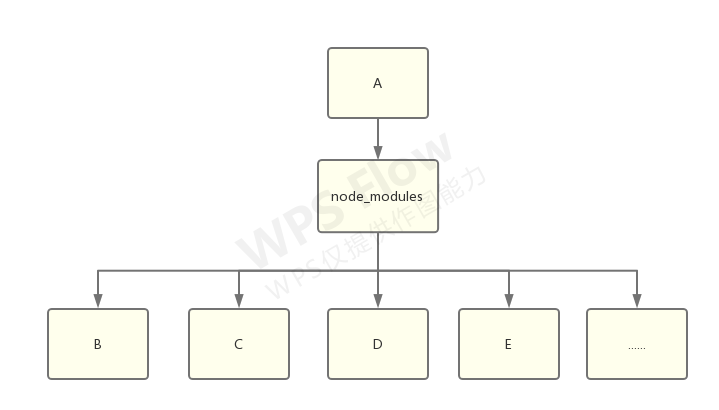
初版 npm 带来的文件结构,是嵌套结构:
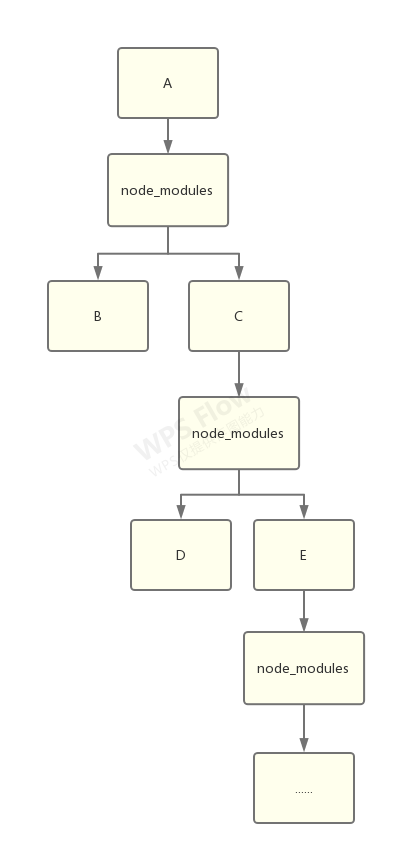
一切都很美好,除了…
node_modules 堪比黑洞,图来自 https://github.com/tj/node-prune 。
node_modules 体积过大
显而易见的问题,如果一个库,比如 lodash,被不同的包依赖了,那么它就会被安装两次。这种形式的结构很快就能把磁盘占满。rm -rf node_modules 成为了前端程序员最常用的命令之一。
node_modules 嵌套层级过深
只有当找到一片不依赖任何第三方包的叶子时,这棵树才能走到尽头。因此 node_modules 的嵌套深度十分可怕。
具体到实际的问题,相信早期 npm 的 windows 用户都见过这个弹窗:
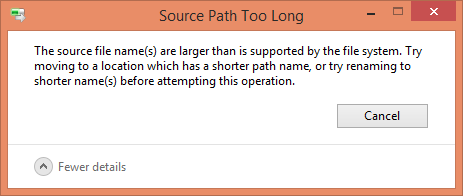
(node_modules 文件夹无法删除,因为超过了 windows 能处理的最大路径长度)
详情见 这个 issue 。
Yarn & npm v3

2016 年,yarn 诞生了。yarn 解决了 npm 几个最为迫在眉睫的问题:
- 安装太慢(加缓存、多线程)
- 嵌套结构(扁平化)
- 无依赖锁(yarn.lock)
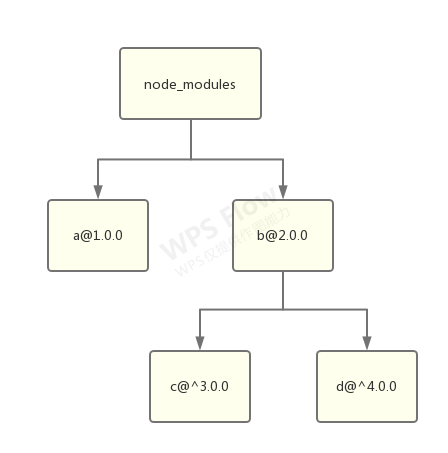
yarn 带来对的扁平化结构:
扁平化后,实际需要安装的包数量大大减少,再加上 Yarn 首发的缓存机制,因此依赖的安装速度也得到了史诗级提升。
依赖锁
相比于扁平化结构,可以说 yarn 更大的贡献是发明了 yarn.lock。而 npm 在一年后的 v5 才跟上了脚步,发布了 package-lock.json。
在没有依赖锁的年代,即使没有改动任何一行代码,一次 npm install 带来的实际代码量变更很可能是非常巨大的。 因为 npm 采用 语义化版本 约定,简单来说,a.b.c 代表着:
a主版本号:当你做了不兼容的 API 修改b次版本号:当你做了向下兼容的功能性新增c修订号:当你做了向下兼容的问题修正
问题在于,这只是一个理想化的“约定”,具体到每个包有没有遵守,遵守得好不好,不是为我们所控的。 而默认情况下安装依赖时,得到的版本号是类似 ^1.0.0 这样的。这个语法代表着将安装主版本号为 1 的最新版本。
虽然可以通过去掉一级依赖的 ^ 指定精确版本,但是无法指定二级、三级依赖的精确版本号,因此安装依然存在非常大的不确定性。
因此,为了解决这个问题,Yarn 提出了“锁”的解决方案:精确地将版本号锁定在一个值,并且在安装时通过计算哈希值校验文件一致性,从而保证每次构建使用的依赖都是完全一致的。
一个 yarn.lock 文件示例片段:
# THIS IS AN AUTOGENERATED FILE. DO NOT EDIT THIS FILE DIRECTLY. |
“双胞胎陌生人”问题
这个词在英文中是 doppelgangers,意思是它们长得很像,但是除此以外又完全没有其它的关联。
想象一下有一个 library-a,它同时依赖了 library-b、c、d、e:
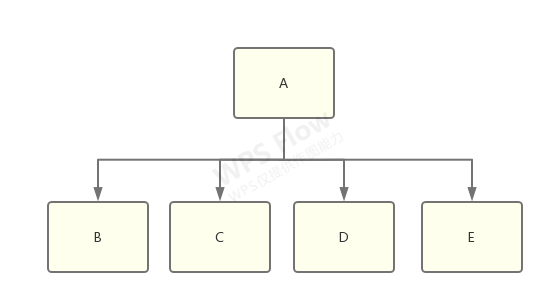
而 b 和 c 依赖了 f@1.0.0,d 和 e 依赖了 f@2.0.0:
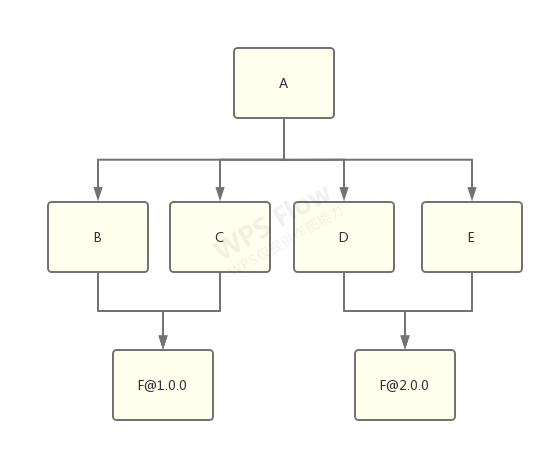
这时候,node_modules 树需要做出选择了,到底是将 f@1.0.0 还是 f@2.0.0 扁平化,然后将另一个放到嵌套的 node_modules 中?
答案是:具体做那种选择将是不确定的,取决于哪一个 f 出现得更靠前,靠前的那个将被扁平化。
举例,将 f@1.0.0 扁平化的结果:
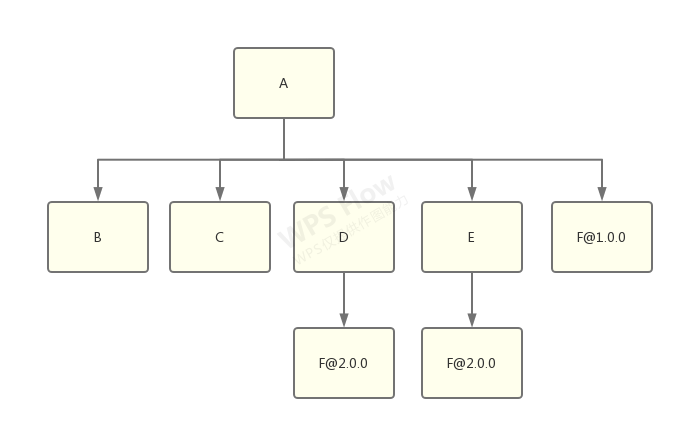
将 f@2.0.0 扁平化的结果:
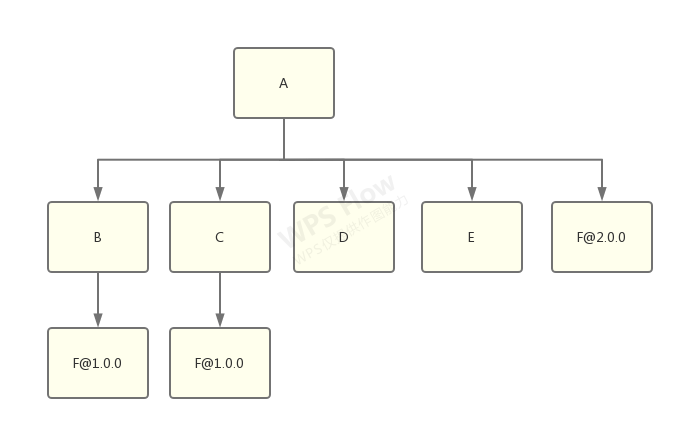
无论如何,这个选择必须做,我们必然会在 node_modules 中拥有多份的 library-f,窘境将是无法避免的。因此它们也就成为了“双胞胎陌生人”。
其它编程语言没有这种问题,这是 Node.js & npm 独有的。 这种问题会造成:
- 安装更慢
- 耗费的磁盘空间更大
- 某些只能存在单例的库(比如 React 或 Vue)如果被同时安装了两份则会出现问题
- 当使用依赖 f 使用了 TypeScript 时会造成 .d.ts 文件混乱,导致编译器报错
- 假设 f 有一个依赖 g,项目里也存在 g 的“双胞胎陌生人”,那么根据 Node.js 的依赖查找原则(从当前目录逐级向上查找),两个 f 有可能会检索到不同版本的 g,这可能导致高度混乱的编译器错误。
“幽灵依赖”问题
假设我们有以下依赖:
{ |
理论上来说,我们项目的代码中可以使用的依赖只有 minimatch。但是实际上,以下代码也能运行:
var minimatch = require("minimatch") |
这是因为扁平化结构将一些没有直接依赖的包也提升到了 node_modules 的一级目录,但是 Node.js 并没有对其校验。所以引用它们也不会报错。
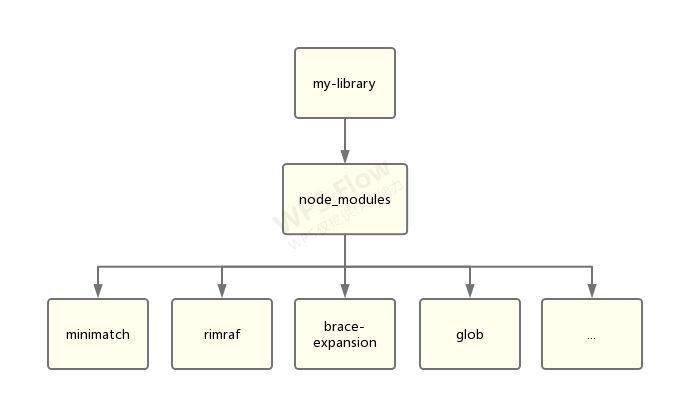
这种情况带来的问题:
- 在没有显式指定“间接依赖”的版本号的时候,如果它被依赖到它的包做了大版本升级,存在不兼容的 API 变更,那么应用代码很可能就会跑不起来
- 没有显式指定依赖带来的额外管理成本
Workspace
Yarn 1.0 带来的另一个特性是 workspace,也是 monorepo 能够发展起来的一个重要原因。
假设我们有一个 workspace-a,它依赖了 cross-env:
{ |
还有一个 package-b,它依赖了 cross-env 和 package-a:
{ |
那么这时候在使用 workspace 模式安装的话,将得到以下结构:
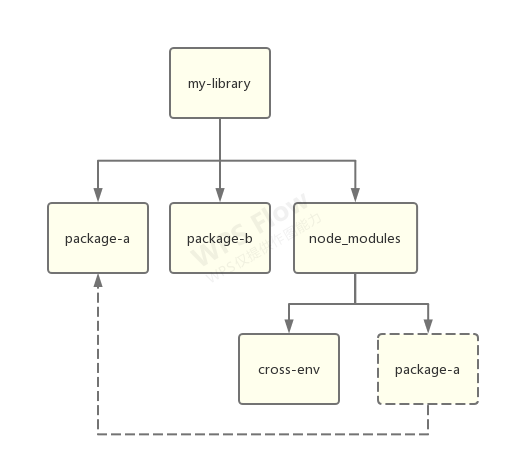
其中,node_modules 中的 package-a 只是实际文件的链接。也就是说,Yarn workspace 模式可以将项目底下的子项目的依赖提升到根目录来进行扁平化安装,这样可以节省更多的磁盘空间,带来更快的安装效率,也可以使得项目管理更方便。
但是,结合上面所提到的两个问题,workspace 带来的问题只会更多,不会更少。这里就不详细展开了,应用级 Monorepo 优化方案 这篇文章总结得很好。
Lerna

由于 Workspace 的特性实在是太过好用,monorepo(multi-package repositories, multi-project repositories)开始迅速发展。许多知名的开源库开始转向 monorepo,还有更激进者将 monorepo 使用在业务项目中。Lerna 顺势而生。
但是,Lerna 并不是 Node.js 包管理器的一部分,也没有解决任何已存在的包管理器问题。它所做的只是将 monorepo 的使用体验变得更舒服了,比如:
- 可以更方便地创建 monorepo
- 可以更方便地管理 packages 中的依赖项
- 可以一键发布 packages、自动根据 git commit log 更新每个 package 的 changelog
- 等等
仅此而已。按照官网的说法,Lerna 所做的事情是“优化了这个流程(optimizes the workflow)”。
pnpm

P for Performance —— 性能更强的 npm。
pnpm 复刻了 npm 的所有命令,同时在安装目录结构上做了大幅改进。
善用链接
这里通过一个例子来看 pnpm 的安装结构特点。
安装依赖
假设我们要安装一个 foo 包,它依赖了 bar。首先,pnpm 会先将所有直接和间接依赖安装进来,并“摊平”(注意,这里没有扁平化算法,是字面意义上的摊平):
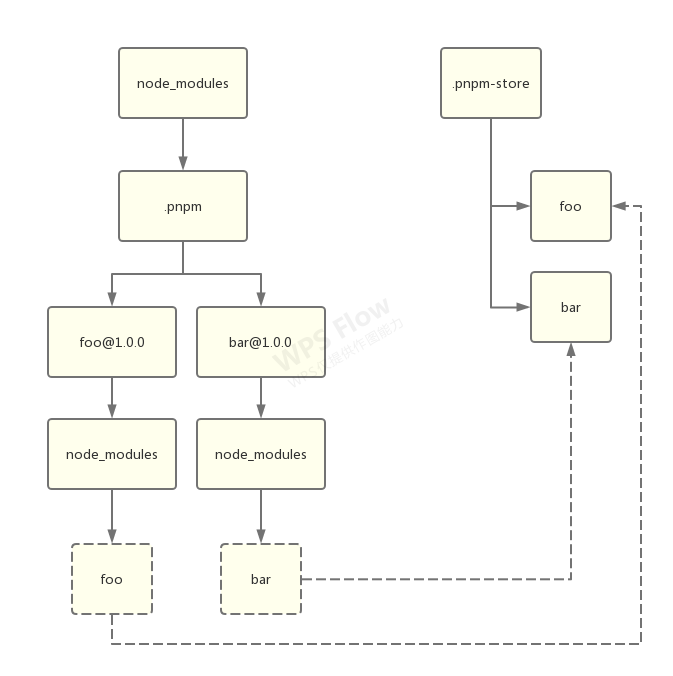
你可能注意到,在 xxx@1.0.0 的目录下面,首先是一个 node_modules 目录,然后才是 xxx,这么做的目的是:
- 允许包引用自己
- 将包自身和其依赖打平,避免循环结构。在 Node.js 中,这么做其实跟原本的样子并没有太大区别。
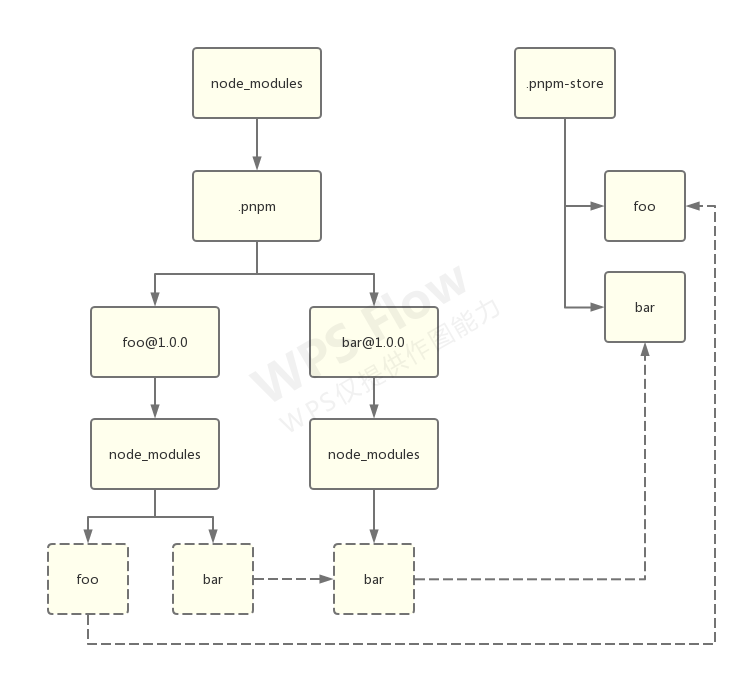
处理间接依赖
然后,在 foo 的平级创建一个 bar 文件夹,链接至 bar@1.0.0 下面的 bar:
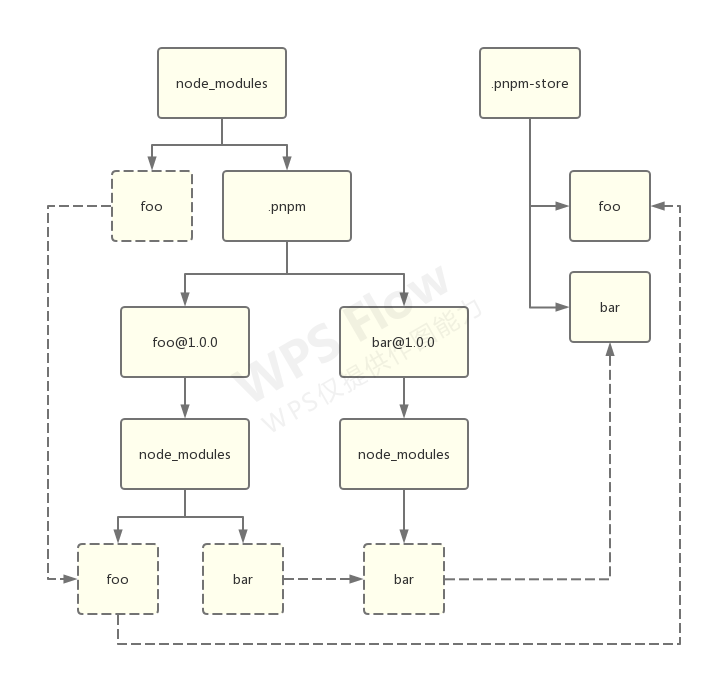
处理直接依赖
在顶层 node_modules 创建一个 foo 硬链接,连接至 foo@1.0.0 中的 foo,以供应用访问:
处理更深层次的间接依赖
假设 foo 和 bar 都依赖了 qar@2.0.0:
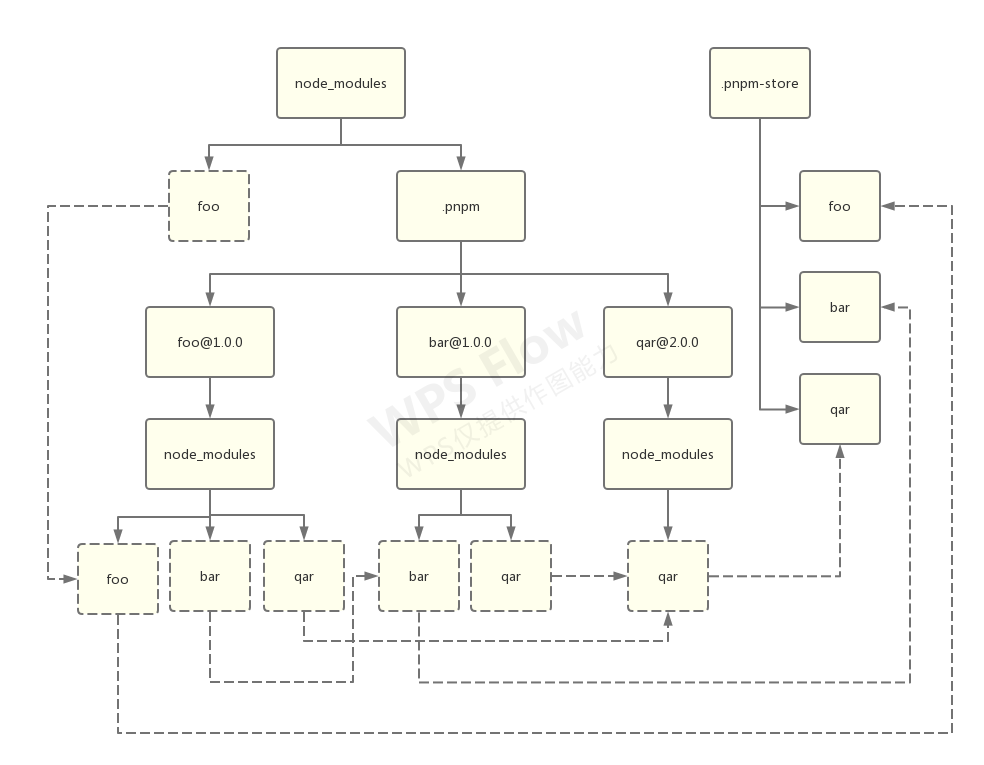
可以看到,虽然依赖层级变深了,但是文件树并没有变深。这就是 pnpm 的特色结构:通过硬链接创造的依赖“树”。
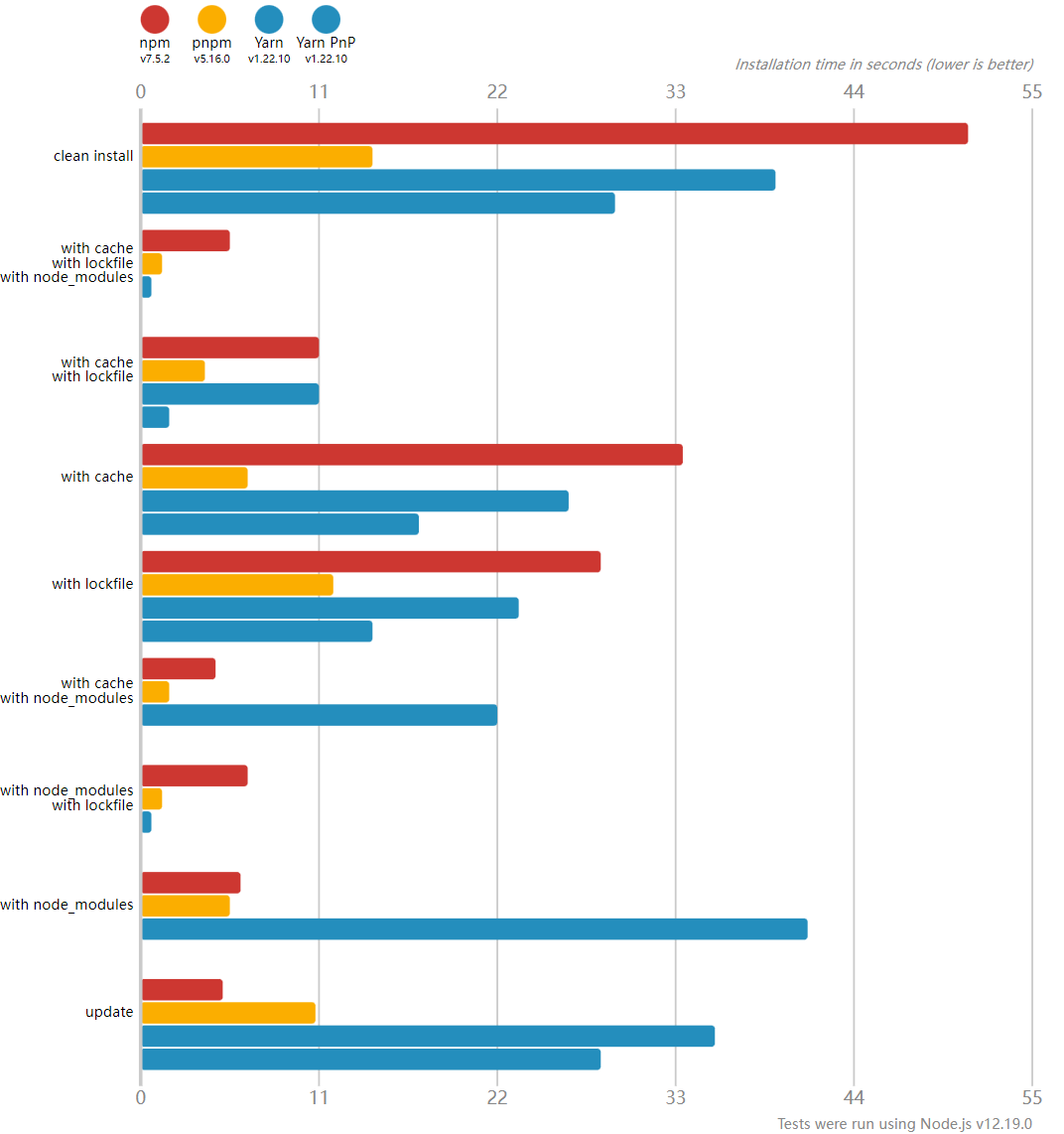
性能对比
由于硬链接的巨大优势加成,在绝大多数情况下,pnpm 的安装速度都要比 yarn 和 npm 更快:
自动解决锁冲突
pnpm 能够自动解决锁文件的冲突。当冲突发生时,只需要运行一次 pnpm install,冲突就能自动由 pnpm 解决。很人性化。不过,据说 Yarn 从 1.0 版本开始也提供了类似的功能。
存在的问题
- 并不是所有项目都能“无痛”迁移至 pnpm。由于历史原因(扁平化),我们的应用或者应用的某些依赖并没有很好地遵循“使用到的包必须在 package.json 中声明”这一原则,或者把它当作一项 feature 享受其中。这样的话迁移至 pnpm 会导致原本会被提升到顶层的扁平化依赖重新回到正确的位置,从而无法被找到。如果问题出在应用上,那么只需要将依赖写入 package.json 即可。但是如果出在依赖就比较棘手了。不过官方也提供了解决方案。
- 由于特殊的安装结构,以往一个很有用的打补丁工具 patch-package 用起来就不是那么顺手了。
Rush

Rush 是微软出品的一款 monorepo 管理工具。与 Lerna 不同的是:Rush 不仅做了许多“优化流程”的工作,还提供了一套与 pnpm 十分类似的硬链接目录结构方案来解决超大型项目中的依赖管理问题。
虽然它声称支持全部的三种包管理工具,但是:
- 配合高版本 npm 使用时有 bug,只能使用 4.x 版本
- 配合 Yarn 使用时无法启用 workspace,因为这会跟硬链接方案冲突
- 只有在配合 pnpm 使用时才能解决“双胞胎陌生人”问题
很显然,如果想要正常使用,pnpm 几乎是唯一选择。
这里简单列出一些 Rush 提供的特色功能:
- 顺序构建:自动检测包的依赖关系,按照从下至上有序构建
- 多进程构建:对于可以同时构建的包,开启多个 Node.js 进程同时构建
- 增量构建:只对发生了变化的包,以及所有受影响的上游或下游包启动构建,支持缓存构建产物
- 增量发布:自动检测需要发布的包并执行发布,甚至可以将发布任务设置为定时执行
- 等等……
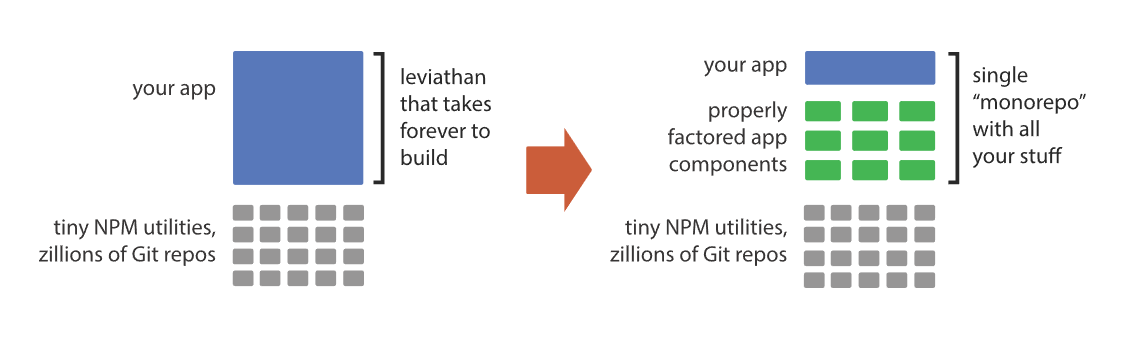
总的来说,微软的一套理论是:企业的项目(不管是业务还是基础)都应该尽可能地放在一个超大型仓库中来管理。并且微软声称自己确实是这么做的(见 Rush: Why one big repo⁈ )。Rush 的目的也是为了解决这套方法论的后顾之忧,比如:
- npm 扁平化结构的各种问题
- 项目逐渐庞大以后的构建速度问题
- 项目如何发布的问题