Node.js Web Spider Note - 1
项目地址:https://github.com/wxsms/zhihu-spider
简介:使用 Node.js 实现的一个简单的知乎爬虫,可以以一个用户为入口,爬取其账号下的一些基本信息,关注者,关注话题等。再通过关注者的 ID 继续爬取其他用户,以此循环。
实现功能:登录知乎(因为调用一些知乎 API 需要保存 session),解析页面,访问 AJAX API,保存到数据库。
执行流程
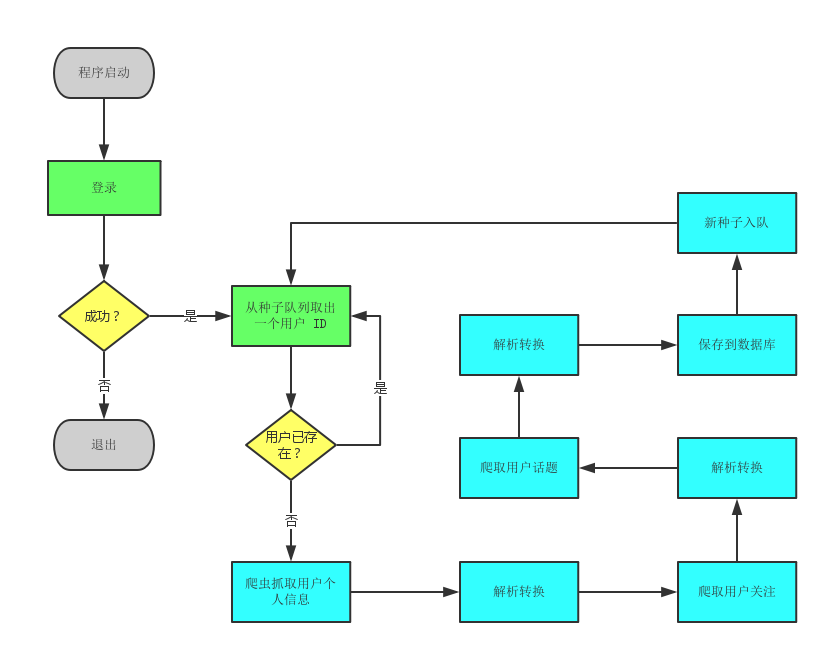
蓝色部分的任一流程出现失败或错误,程序都会直接返回到“从种子队列取出一个用户ID”这一步。因为作为一个完整的知乎用户来说,它应该是包含了个人信息,关注以及话题的,缺失一项会导致其失去很大部分的意义。
技术栈
本程序以 Node.js 为实现核心(本机版本 v6.5.0),用到的依赖很少,如下:
"dependencies": { |
程序解析
程序源代码在代码仓库的 src 目录下,目录结构:
├─config |
配置相关以及通用模块
config 目录主要放置一些程序的配置文件,比如用来登录知乎的用户名和密码,想要抓取的用户种子,数据库连接地址,以及 log 的配置。
constants 目录下是一些对知乎的特定配置,如 url 地址、规则,以及知乎 API 的一些信息,如表单、请求头格式等。
util 目录下目前是放置了一些数据库以及 log4js 的初始化方法,如自动扫描 models 加载以及创建 log 目录等,以便于在程序入口处调用。
models 则是 mongoose 的各种 schema了,用于持久化。
登录模块
登录虽然不是爬虫的重点,但却是必不可少的前提。因为对于知乎网站来说,不登录的话只能看到单个用户的个人页面,想要再前往关注者页面就不可能了。这就造成一个问题:爬虫无法持续工作。
因此,此模块的主要职责是,在爬虫运行的过程当中保证已登录状态。
此模块放置在 http/session 中。
爬虫模块
程序核心之一,同时也是最容易出现问题的地方(尤其是启用多线程以后),负责发送 Http 请求并接受响应。
除了简单的单次请求以外,因为一些特定的原因,里面还涉及到了递归请求。
转换模块
程序核心之一,负责将爬取回来的 HTML 文本、API 返回体等转换成 model 对象,没什么技术含量,体力活。
Service
其实就是将单次爬取的整个流程定义封装好,供主程序调用。
同时也负责爬取结果的储存,以及用户种子队列的管理。
重点难点
模拟登录
这次经历让我意识到什么都靠 Google 也有不行的时候,因为爬虫这东西,虽然肯定也有别人做过,但是基本上都过时了,人家网站早更新了,真刀真枪还是得靠自己。
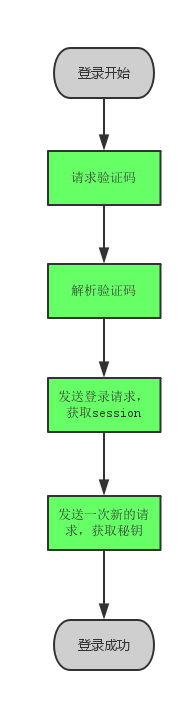
整个过程虽然简单,但是由于经验匮乏,还是走了不少弯路。最终总结出来的必须步骤如下:
代码如下:
function login(_user) { |
(目前并没有在所有地方都用上 async await,之后改过来)
获取验证码很简单,但是要注意的是把 response 里面的 set-cookie 信息保存起来添加到一会要登录的请求上去,因为不这么做的话,知乎服务器不认为登录那一次请求跟这个验证码有什么关系。
“解析验证码”这一步目前是这个程序最难看(难看,不是难)的地方,因为用的是土法炼钢:人眼解析。我尝试过用一些通用的验证码识别库去做自动化,但是正确率太低,而且知乎它的验证码有随机两套字体,反正好像训练起来也麻烦,所以就没继续研究下去了,毕竟不是爬虫主体,而且只需要在程序启动的时候输入一次即可。
登录请求的模拟,可以在知乎网站上使用浏览器的开发控制台启用“任意 XHR 断点”来截获网站发送的真实登录请求以及服务器返回来进行伪造。实际上就是填一个表单 POST 出去,然后返回的时候把 response 里面的 set-cookie 信息保存起来添加到以后要使用的所有请求的 header 上去就行了,因为服务器它就是靠这一堆 cookie 值来判断客户端所处的会话。
最后就是那个所谓的“秘钥”,网站上的名字叫 xsrf ,知乎在这里做了一些手脚。它在 set-cookie 中并没有提供这一串秘钥,但是如果我要请求它的 API,那么 cookie 里面就必须有这个键值对,明显网站是通过 JS 动态加进去的。然而我没有必要这么做,只需要在一开始的时候就把它拿到,然后以后每次请求都带上它就可以了。至于怎么拿也很简单,知乎每个页面都有的隐藏的输入框,里面的值就是。
xsrfToken = $('input[name=_xsrf]').val(); |
这四步做完以后,程序就成功登录了。
获取关注
去到知乎的关注者、已关注页面可以发现,内容是随着页面滚动逐步加载的,因此这里存在一个 API 可以使用,无需爬页面。使用浏览器开发者控制台,我们可以截取到 API 的详细信息,以下是我总结的一个:
userFollowers: { |
form 是 API 需要发送的表单,而 header 则是这次请求额外需要的 header(指包括登录获取的 header)。
由于它这个是按 page 来的,每次请求最多只会返回 20 条记录,到底了就会返回空数组,因此我做了一个 Promise 递归来实现这个功能。另外,由于有的用户关注加起来上万条,全部遍历完实在是太慢(不知道会不会一去不回),所以我把抓取的总数限制在了 100 条。至于总数的这个数量,在其它地方可以获取到,不需要通过这里获取,所以无所谓。
function resolveByPage(user, offset, apiObj) { |
持续工作
爬虫如何持续工作这个问题一开始我是挺头疼的,就是说当一次任务结束以后,要如何自动开始下一次任务。由于全是异步操作,直接 while 1 肯定要炸。
后来看到 async await 语法,终于写出了一个可工作的版本。(Node.js v6.5.0 还没有原生支持 async await,所以用到了一个库)
let next = async(function (threadId) { |
程序执行到 await 关键字的地方就会阻塞,直到语句返回再继续。
至于多线程,直接简单暴力:
let main = async(function () { |
这样,执行 main 方法,程序就有 5 个线程同时工作了。
目前的问题
效率
5 条线程还是太慢,一小时大约能抓 1000 个用户的样子,但是我又不能再多开,再开线程请求数就爆了,各种报错、失败,得不偿失。
我在想是不是能再开几个 Node.js 进程同时跑这个程序。质量不行数量来补。
09/12/2016 更新:这个办法不行。请求数限制是在服务器端做出的。貌似无解。
稳定性
这个是目前很头疼的问题。我发现程序在跑一个小时或者两个小时以后,5 条线程就只剩下一条或者两条还在工作,其它的都失踪了,或者干脆全都死在那里了。其实我知道它们没死,只不过不知道为什么卡住了。
第一次发现的时候觉得有点逗,感觉就像自己生了五个孩子后来死剩两个一样。
09/12/2016 更新:目前发现了一个原因,即有些知乎用户的个人主页被屏蔽了,导致解析失败,但是又没有 catch 导致线程无限挂住。解决这个以后问题依然存在,高度怀疑是因为 session 过期。
09/14/2016 更新:果然是 session 过期的原因。在登录的表单中加入一个字段 remember_me: true 以后,线程死掉的问题就解决了!Excited!